Leaderboard
Ranking
Top models settle in the low 40s while humans nearly solve the benchmark — a gap of 46 points that current MLLMs have yet to close.
To include your model in the leaderboard, please email pinzhihuang23@gmail.com with evaluation logs and setups.
Benchmark
What is VSTAT?
We introduce Visual STAte Tracking benchmark (VSTAT), a video-based benchmark designed to diagnose visual state tracking in MLLMs. VSTAT consists of 834 video clips paired with 1,500 questions drawn from synthetic, self-recorded, and real-world videos in the wild that contain procedural processes.
Each task is constructed so that the answer cannot be read off any single keyframe or a few salient moments: critical events may be hidden, visually similar to each other, or distributed across multiple entities and moments. Thus, models must continuously perceive and integrate events throughout the entire video stream. The tasks in VSTAT vary in the complexity of state to be tracked, and exhibit various perceptual challenges in extracting state from video; for instance, in the Rubik’s cube task, the model must track a specific cubie even when it is occluded in some frames.
Surprisingly, while these questions can be easily answered by humans, state-of-the-art MLLMs perform far below humans and only modestly above answer-prior baselines.
Examples
A glimpse across 39 tasks.
One representative clip per task, drawn from synthetic Blender renders, in-the-wild YouTube footage, and our own recordings. Click a card to see the question, options, and the ground-truth answer.
Why current MLLMs struggle on VSTAT.
Beyond reporting numbers, we localize where the bottleneck lies. Across two complementary studies, visual perception — not textual reasoning — emerges as the dominant cause of failure.
This gap stems from visual perception, not reasoning.
We compare the same model under two parallel conditions: the rendered video versus a hand-written textual transcription of the same visible states and events. A large gap implies the bottleneck is perception, not reasoning.
Question
How many times did the Pink face touch the floor?
Video
The model watches the actual rendered video.
Text Transcription
The model reads a hand-written transcription of the same events.
The die starts with the following three visible faces: (Red, Green, Blue).
The die is then moved as follows: roll up, roll down, roll left, …
After each move, the three visible faces become: (Green, Pink, Blue), (Red, Green, Blue), (Blue, Green, Pink) …
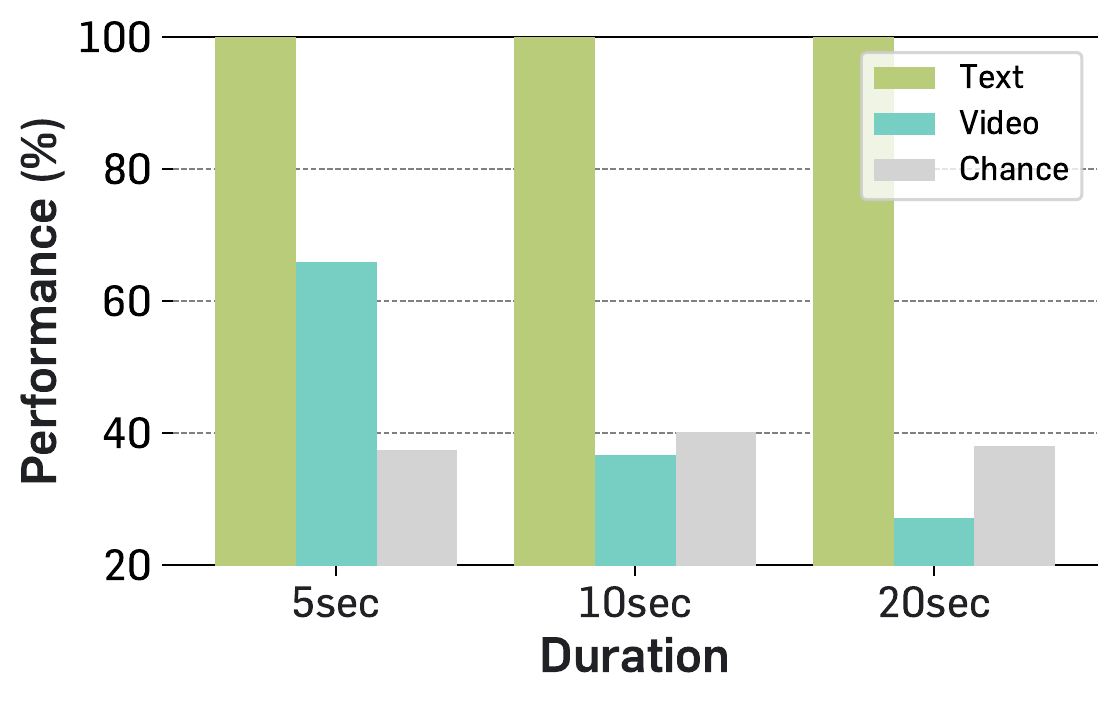
State-of-the-art MLLMs solve these tasks perfectly from text, yet drop toward random-guess on video — even at 5 seconds, where context length is negligible. The perceptual gap is so severe that we had to provide the transcriptions by hand — state-of-the-art MLLMs themselves fail to transcribe even these synthetic videos into text.
Visual perception appears to be a main bottleneck for models on VSTAT.
What perceptual challenges does VSTAT contain?
We consider six categories tied to factors that make video perception difficult, illustrated below with one representative clip per category.
When do current MLLMs fail to solve VSTAT?
Comparing each video with the model’s thinking trace, we identify three recurring failure modes. More than 50% of failures stem from event recognition, suggesting the dominant bottleneck of current MLLMs lies in low-level perception, rather than visual reasoning.
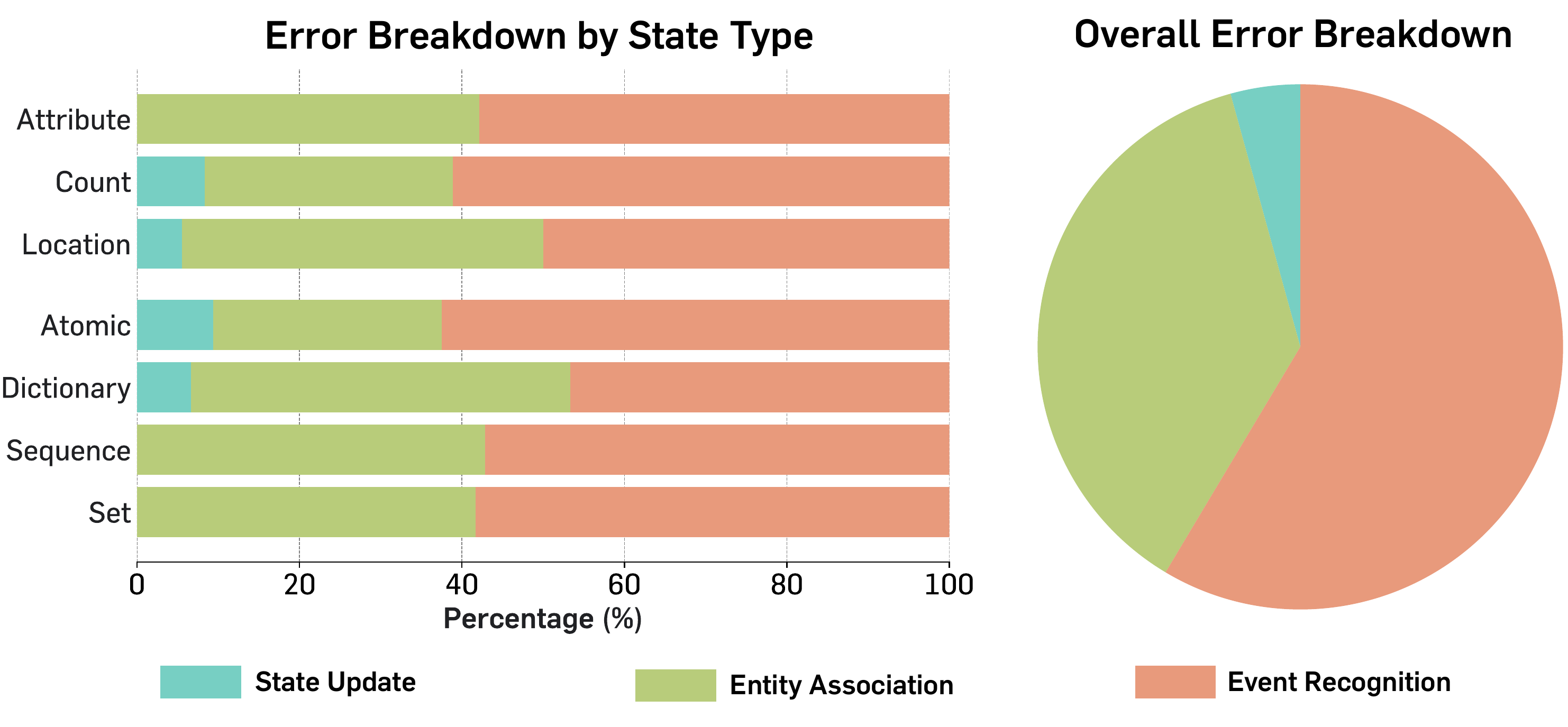
The model misreads what just happened.
Even for relatively straightforward events, the model can fail to recognize them. In a cup-shuffle case, a person swaps the center and right cups, but the model identifies the event as “the Left and Right cups are swapped”, leading to an incorrect final answer. In harder cases, it may hallucinate the entire event trace.
It loses track of who did what.
The model often fails when the state requires consistent association with a specific entity among visually similar objects. In a volleyball example, all players wear identical uniforms; the model correctly identifies each ball-touch event but assigns a new random jersey number each time, even when the same player handles the ball repeatedly.
It forgets to apply the change.
The model correctly recognizes events and tracks entities, yet fails to update the state needed for the answer. During a third swap, it correctly notes that “Center and Right cups are swapped” but keeps the target cup at Center instead of moving it to Right. Common when tracking continuous trajectories.
Neither thinking nor agents fix it.
Two natural fixes — more thinking and agentic frameworks — both fail to rescue performance. Thinking budgets typically hurt on VSTAT; agents stay near chance level.
More thinking, less accuracy.
Increasing the thinking budget from low to high (or enabling thinking for instruct models) consistently degrades accuracy on VSTAT. With higher perceptual complexity, a larger thinking budget appears to increase the likelihood of hallucination.
| Model | Setting | Score | Δ |
|---|---|---|---|
| Gemini-3.1 Pro | low → high | 44.4 → 43.9 | −1.1% |
| Gemini-3.0 Flash | low → high | 39.8 → 38.8 | −2.5% |
| Qwen3VL-8B | w/o → w/ | 33.2 → 28.2 | −15.1% |
| InternVL3.5-8B | w/o → w/ | 30.6 → 30.2 | −1.3% |
Agents stay near chance.
We evaluate one video agent (AVP) and two coding agents (Codex with GPT-5; Claude Code with Opus 4.7) on a small n=39 subset. All sit at near-chance level, despite their strong performance on text-based tasks — reinforcing that the bottleneck is visual perception.
| Method | Avg. |
|---|---|
| Chance level (Frequency, n=39) | 50.8 |
| Gemini-3.1 Pro | 52.6 |
| Gemini-3.1 Pro + AVP (video agent) | 43.6 |
| Claude Code (Opus 4.7, coding agent) | 37.6 |
| Codex GPT-5 (xhigh, coding agent) | 53.4 |
Coding agents typically spend considerable time and tokens to answer a question — a single question takes ~30 minutes on average, largely because they produce inconsistent intermediate results that confuse the model itself. Video agents commit too early to their initial observation, sampling the video at a fixed low frame-rate (typically 1 FPS) and synthesizing an answer from a single round of evidence collection without verification.
Citation
Reference the benchmark.
@article{vstat2026,
title = {Benchmarking Visual State Tracking in Multimodal Video Understanding}
author = {Sihyun Yu and Nanye Ma and Pinzhi Huang and Hyunseok Lee and Shusheng Yang and June Suk Choi and Ellis Brown and Oscar Michel and Boyang Zheng and Jinwoo Shin and Saining Xie},
year = {2026},
journal = {arXiv preprint arXiv:2606.03920},
}